
Cuando analizamos un conjunto de textos, en concreto tweets, nos surge un problema a la hora de detectar temáticas (o topics) existentes en ellos, ya que si tratamos con un número de tweets extremadamente numeroso esto será inabarcable para una o varias personas.
Una solución a este problema puede consistir en el uso de los denominados Topic Models. Estos se definen como modelos jerárquicos bayesianos que se aplican a una serie datos discretos, tales como un conjunto de textos, en nuestro caso tweets, y en el que se consideran a los elementos del conjunto como mezclas de un número determinado de topics, que aparecen con cierta probabilidad o frecuencia en cada elemento del conjunto.
En 2003 David Blei, Andrew Ng y Michael Jordan publicaron un artículo llamado “Latent Dirichlet Allocation (LDA)”, en el cual se describía un novedoso y revolucionario Topic Model. El LDA es un modelo jerárquico bayesiano de tres niveles, en el que se considera para los topics una distribución multinomial, cuyo parámetro n-dimensional, (siendo n el número de topics existentes), sigue, a su vez, una distribución de Dirichlet.
Uno de los proyectos a los que hemos aplicado este modelo es uno formado por 30000 tweets y basado en la escucha de una serie de bloggers influyentes del mundo de la moda entre los meses de Septiembre y Octubre de 2014, del que pretendíamos conocer sus tendencias predominantes.
Uno de los topics más importantes que hemos encontrado con un volumen del 7,2% del total, es uno relacionado con la dieta. En el siguiente gráfico, podemos comprobar como conforme empieza a terminar el verano, el físico deja de tomar importancia en las personas y de ahí la bajada de frecuencia en este topic. Observamos como pasa de un 0.1% a un 0.05%, casi la mitad de la cifra anterior.

Otro ejemplo es el obtenido en cuanto a la moda de Otoño, teniendo un volumen de datos con respecto al total del 7,7%.
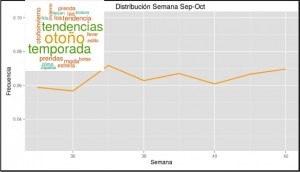
Esta gráfica, en cambio, es más estable pero aún así, podemos observar un pico coincidiendo con la Nueva York Fashion Week y Madrid Fashion Week entre la primera y segunda semana de Septiembre pasando de una frecuencia de aproximadamente 0.6% a cerca de un 0.8%.
Por último, como consecuencia también de las tendencias de las modelos en las pasarelas, es curioso ver como se trata el tema del peinado en las modelos, y como esto afecta al público. A continuación podremos observar, aunque con un volumen menor que en las anteriores, el 6.7% del total, como en la gráfica se ejerce un pico de frecuencia de esta temática, pasando de menos de un 0.06% a más de un 0.1%.

Al aplicar LDA a este y a otros proyectos relacionados con tweets hemos encontrado cierta desambigüedad en el conjunto final de textos que pertenecen a un topic (o topics) en concreto, es decir, cierta mezcla de temáticas, causada a raíz de la escasez de palabras contenidas en los tweets y que limitan este modelo para este conjunto concreto de textos.
Para evitar esta desambigüedad actualmente estamos realizando nuevas pruebas con otros Topics Models actuales, en concreto el Structural Topic Model (STM), que permite incluir metadata, (o grupo de características de los tweets, como puede ser autor, localización, etc), en el modelo, lo cual evita en gran parte el anterior problema, permitiendo una detección de topics más eficaz.



0 comentarios